|
|
En los últimos años la tecnología que permite la construcción de conjuntos redundantes de discos (RAID), ha progresado mucho, haciéndola mucho más asequible, segura y barata. El precio de los discos y las controladoras es mucho más barato lo que hace a las configuraciones RAID y especialmente RAID-5 hallan entrado a saco en la mayoría de los sistemas.
Lamentablemente junto al crecimiento de su presencia en el mercado, han ido apareciendo leyendas que han llevado a sorpresas a la hora de implantar RAID en sistemas productivos.
En esta introducción se trata de explicar el funcionamiento de las diferentes clases de RAID hoy día soportadas, para entender desde la base la configuraciones propuestas en la mayoría de sistemas del mercado.
El principal objetivo de las diferentes configuraciones RAID es el de superar el rendimiento y la fiabilidad de sistemas basados en un único dispositivo o disco.
|
|
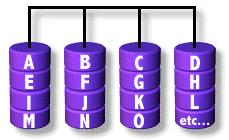
RAID-0 o stripe (división entre discos) es el concepto que está por debajo de la mayoría de las configuraciones RAID. Es fundamental conocer RAID-0 antes de comprender el funcionamiento del RAID-5.
En RAID-0, los datos del volumen lógico están distribuidos en los discos subyacentes dividiendo los datos en bloques. Los bloques del volumen lógico se asignan a los dispositivos físicos que lo componen de forma circular: El primer bloque va en el primer disco, el segundo al segundo disco, y así hasta que se acaban los discos y se vuelve al primero.
El tamaño del bloque es lo que veremos a veces como chunk size y el número de discos en el volumen lógico stripe width (ancho de reparto en una traducción libre). Ambos parámetros tienen una gran incidencia en el rendimiento del conjunto de discos dentro del volumen lógico.
Una petición de lectura sobre un RAID-0, mayor que el chunck size será atendida por más de un disco. Esto permite y requiere la activación de múltiples dispositivos y el uso de varios caminos de acceso a los datos (tarjetas SCSI, canales de E/S, discos, ). El uso de varios dispositivos mejora el rendimiento y ,en concreto, permite superar la limitación del tiempo de transferencia de un solo disco.
Una petición lógica en RAID-0, es dividida en peticiones físicas más pequeñas, que son programadas secuencialmente pero servidas en forma concurrente.
Osea que una petición (de lectura) única genera comandos para el subsistema de E/S, atiende las interrupciones asociadas a los dispositivos de E/S, y forma un único resultado lógico con las respuestas de las diferentes operaciones, que es lo que espera el usuario.
En el caso de lecturas secuenciales, como la generación de los diferentes comandos para cada E/S y el atenderlos al terminar no pasa de unos pocos milisegundos, la mejora del rendimiento es casi lineal según se van añadiendo discos al sistema RAID-0.
Para lecturas aleatorias las previsiones no son tan optimistas. Cuando el brazo de la cabeza lectora tiene que moverse para buscar una nueva pista dentro del disco, el tiempo de entrada salida está muy influenciado por el tiempo de búsqueda y la velocidad de rotación mucho más que por el tiempo de transferencia de los datos que puede representar un dos por ciento del tiempo total de E/S.
Un par de leyendas asociadas al RAID-0:
|
Es
siempre mejor dividir las peticiones de E/S, para que las partes puedan
ser transferidas en paralelo. FALSO
|
No es siempre cierto, cada operación
de E/S tiene asociadas varias operaciones SCSI, cuatro por lo menos. Para
peticiones pequeñas es mucho mayor el esfuerzo de preparar y procesar
la E/S que la transferencia de los datos. Hay que tener cuidado de no tener
un chunk size demasiado pequeño precisamente por esto. No usar
tamaños menores de 4 u 8 kbytes.
|
El
stripping no mejora la E/S aleatoria. FALSO
|
De hecho aunque no mejora los accesos aleatorios individuales, si puede mejorar (y bastante) el rendimiento medio del sistema de discos en entornos en los que domina el acceso aleatorio. La explicación a esta aparente paradoja está en el hecho de que se reparte mejor el acceso a los discos: hay menos tiempo de espera en cada una de las colas.
El stripping reparte los datos del volumen lógico entre los discos que lo forman, dando con el mecanismo perfecto para evitar largas colas. En muchos sistemas el problema de rendimiento es la gran carga de lectura y escritura sobre un solo disco.
Resumiendo: RAID-0 mejora las operaciones secuenciales permitiendo que varios discos funcionen en paralelo; además mejora las aleatorias reduciendo la utilización de disco y reduciendo las colas de espera. Esto es perfecto, ¿no? pues NO. Si uno de los dispositivos físicos asociados al volumen falla todo el sistema lógico deja de funcionar.
|
|
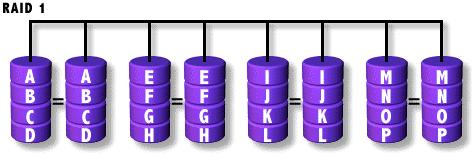
Aunque es un concepto bastante clarito y sencillo, tiene el problema de lo caro que resulta tener el doble de disco del que realmente se necesita.
En la mayoría de los casos el rendimiento las lecturas mejorará en sistemas espejados ya que se disminuye el uso de disco. La mayoría de instalaciones de este tipo permite elegir entre dos políticas de lecturas: round-robin y geométrica.
En round-robin cada lectura sucesiva es atendida por un sub-espejo diferente. Para lecturas aleatorias reparte la carga entre los discos, pero para secuenciales no está tan claro que se gane en rendimiento porque el alternar los accesos entre diferentes discos hay que posicionar cabezas en cada lectura, etc.
En el esquema geométrico cada mirror
es dividido en regiones (una por cada subespejo o submirror), y cada
disco sólo atiende peticiones de la subregión asignada. Por
ejemplo en una división con dos regiones todos los accesos a la
primera mitad del RAID-1 son dirigidos al primer disco, y los accesos a
la segunda mitad, al segundo disco.
|
En
un mirror las escrituras son la mitad de rápidas que las escrituras
en un solo disco FALSO
|
Una escritura típica en un sistema RAID-1 viene a tardar de un 15 a un 20 por ciento más que las escrituras en un solo miembro.
|
|
Estrictamente hablado un RAID-1 sólo trabaja con discos de forma individual. En una configuración RAID 0+1 el espejado coexiste con el stripping; cada uno de los subespejos está distribuido en bloques.
Las lecturas secuenciales mejoran por la
distribución de los datos y las lecturas aleatorias por el uso de
varios discos.
Las escrituras ven empeorado su rendimiento
en un 15 o 20 por ciento comparadas con las de un subespejo.
|
|
Últimamente aparece en el mercado esta nueva configuración en los diferentes gestores de volúmenes como Veritas Volume Manager 3.x. La distinción entre esta configuración y la anterior es un poco liosa inicialmente así que tratemos con un ejemplo para ver las diferencias.
Supongamos que disponemos de 8 discos para la creación de nuestro nuevo volumen.
Si queremos una configuración "0+1" haremos un volumen "troceado" con los cuatro primeros discos y posteriormente lo espejaremos con los cuatro restantes.
Para la configuración "1+0" primero
haremos cuatro volúmenes de un disco y su espejado: El primer disco
con el quinto, el segundo con el sexto, etc. Lógicamente ya no tenemos
ocho discos sino cuatro. Bien, sobre esos cuatro "discos" creamos ahora
un volumen con una configuración en "stripe". Osea que tenemos
un stripe montado sobre cuatro volúmenes de dos discos espejados.
En pruebas de copia de un Gbyte sobre un volumen 0+1 y otro 1+0, este último
se comportó horrible: casi el doble de tiempo.
|
|
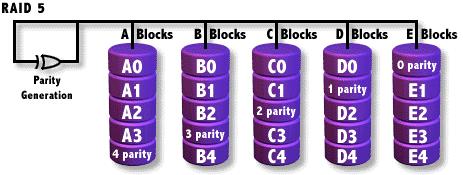
RAID-5 es una extensión de RAID-3
en el que la información redundante se almacena en un solo disco.
RAID-5 hace lo mismo sólo que la información de paridad se
reparte entre los diferentes discos que forman el sistema RAID. Tenemos
información redundante con un coste menor que el espejado de cada
uno de los discos.
Disco 1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Al igual que en RAID-3 , en RAID-5, las lecturas no necesitan acceder a los discos en que se encuentra la paridad, a no ser que uno de los discos no pueda proporcionar sus datos. Por esto y porque RAID-5 distribuye los datos por un disco más que RAID-0 las el rendimiento en lecturas secuenciales es el mismo en ambos sistemas, y un RAID-5 es un poco más rápido en lecturas aleatorias. En escrituras el resultado no es tan prometedor.
Si imaginamos una escritura del bloque D7, vemos que en RAID-0 implica acceso al disco 3, y en RAID-5 hay mucho más trabajo que realizar. Tiene que escribir el dato (disco 3) y el bloque de paridad tiene que ser actualizado. Para eso necesita leer el antiguo D7 y la antigua paridad, calcular la nueva, y finalmente escribir ambos en cada disco. Al final tenemos que una escritura simple conlleva dos lecturas y dos escrituras, es decir: ¡ el cuádruple de carga !. Si la operación de escritura consistiera en modificar los bloques D6 y D7 las cosas se complican.
En estos sistemas aparece en concepto de transacción y commit en dos fases, al igual que en bases de datos distribuidas.
Si el sistema se cae cuando se ha escrito el dato D7 pero no se ha actualizado P1, la información de paridad redundante con es coherente con los datos. Para evitar este desastre los algoritmos RAID-5 (hardware o software) implementan un protocolo de commit en dos fases. Este protocolo necesita de la existencia de un área de log. Los arrays software ejecutan las operaciones de escritura más o menos así:
1.- Lee de los discos para obtener los datos y el cálculo de la paridad. Todos los discos se leen en paralelo.
2.- Calcula el bloque de paridad (a veces se piensa que este proceso en muy costoso: mentira, tarda menos de un milisegundo cuando los tiempos de E/S en los discos es de 3 a 15 milisegundos)
3.- Escribe los datos modificados y la nueva paridad en el log, con la identificación de cada log por si hace falta reaplicar la operación. Esto se realiza en una sola operación de E/S.
4.- Los datos modificados y la paridad se escriben en los discos en paralelo.
5.- Elimina la información del log asociada a la operación.
De aquí sacamos que una operación de escritura lleva: dos lecturas para obtener la información de paridad, el cálculo de la paridad, los escrituras para el commit de dos fases en el log, una escritura para la paridad, y una o dos para los datos.. Es decir una degradación del rendimiento del 60 por ciento.
Para mejorar esto se suele utilizar memoria
no volátil para el almacenamiento de los logs.
En mirror, cuando uno de los discos falla, el subespejo que contiene se pone fuera de proceso (off-line). Hasta que el disco se reemplaza todos los accesos son dirigidos al espejo superviviente, que es el que determina el rendimiento.
En el caso de RAID-3 y 5 el comportamiento
es diferente. Las escrituras son iguales de lentas en modo degradado
que en modo normal. Las lecturas son otra cosa; cuando falla un disco todos
los demás tiene que ser leídos para calcular la información
que falta. En RAID con muchos discos esto puede ser un problema. Si tengo
un RAID-5 de 30 discos y uno de ellos falla, en cada lectura tendremos
que acceder a 29 discos. Es sistemas así las escrituras también
son muy costosas y se suele utilizar como límite seis discos en
una configuración RAID con cálculo de paridad. Luego se pueden
concatenar varios sistemas RAID en un volumen si es que necesitamos grandes
cantidades de disco.
La primera de las conclusiones es que la práctica - el experimento - siempre será mucho más fiable que cuelquier teoría que se exponga tanto en este documento como en cualquier otro que encontremos. Dicho esto, y teorizando, exponemos las siguientes:
Cada una de las configuraciones RAID tiene claras ventajas e inconvenientes. stripping soluciona la mayoría de los problemas de rendimiento asociados a un único disco, pero sólo con stripping nos arriesgamos a que el fallo de un disco sea un desastre en todo el sistema.
El espejado de discos sí nos da redundancia y seguridad en los datos pero es bastante costoso y puede ser inaceptable en sistemas muy grandes en los que lo que realmente se quiere es rapidez.
RAID-5, proporciona seguridad y redundancia en los datos comparable al espejado con una rebaja sustanciosa en el precio final del conjunto. Sin embargo, para algunas aplicaciones, sobretodo aquéllas con uso de escrituras masivas, puede resultar implanteable el coste en términos de rendimiento.
Afortunadamente a la hora de diseñar el sistema de almacenamiento apropiado para una aplicación podemos plantearnos un mix de configuraciones.
En un sistema OLTP deberíamos evitar RAID-5, sobretodo si el tamaño del bloque de base de datos es de 2 ó 4 Kbytes. Las tablas grandes accedidas por un sistema tipo DSS, suelen serlo de forma secuencial y es mayor la cantidad de accesos de lectura que de escritura. Por otro lado en sistemas de este tipo DWH, se utilizan mucho las áreas temporales para ordenar los datos (escrituras); si queremos proteger estas áreas de almacenamiento probablemente elegir RAID 0+1 es la mejor opción.
También al ser éstas áreas temporales en las que la información no tiene mucha importancia podemos elegir RAID 0 y santas pascuas.