Replication
Replication is the process of copying and maintaining database objects
in multiple databases. It supports bi-directional transaction capture
and reapplication, and provides sophisticated conflict detection and resolution.
There are two types of replication, multi-master and snapshot.
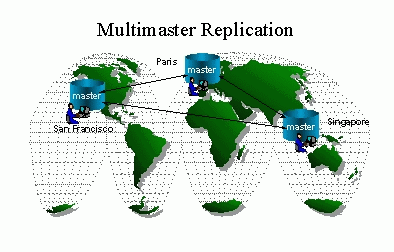
Multi-master replication is used for server-to-server replication.
All servers can be operational, and changes can be made one server will
propagate to the other servers. A good use of this type of replication
is with a call center, where depending upon the time of day, one of the
call centers is open and taking calls. As changes are made to their
database, they are replicated in real time to other call centers.
Later in the day calls may be funneled to a different call center, and
that call center will see the changes made by the other centers.
Transaction consistency is maintained by all servers, and all servers contain
all data.
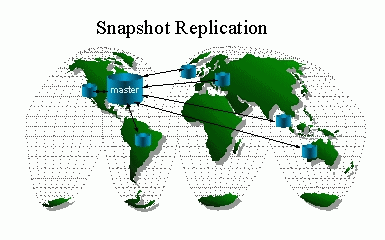
Snapshot replication is used for mass deployments of information
to large numbers of small remote sites. In this case, periodic bulk
transfers containing the final values of changed rows are sent to the remote
databases. In most cases, only a subset of the actual data is sent
to a remote database, as all data is not required at that site. An
example snapshot replication application would be a database containing
product information used by a remote sales force. On a weekly or
monthly basis the product information could be pushed out to the remote
sites for their use. To reduce network traffic or provide additional
security, the push can be architected so only relevant information is sent
to each remote site. For example, a site in the U.S may only need
information on televisions that support North American style broadcasts
(NTSC) whereas a site in Europe may need only the information on televisions
that support European broadcasts (PAL).
Replication and Disaster Recovery
In the event of a disaster or failure at one of the master sites in a multi-master
configuration, service would continue to be provided by the surviving master
sites. In a call center type of application, calls that used to be
handled by the failed site may be routed to one of the other sites.
Alternatively, if the application users at the failed site are unaffected
by the disaster, they could continue handling calls by connecting to one
of the other master sites.
One of the great strengths of replication is that it can replicate transactions
in a heterogenous environment. Servers can be running different releases
of Oracle, and can also be from different vendors. Other disaster
recovery solutions such as Standby Database, Geo-mirroring, and even off-site
backups require the backup server and production server be the same type
and running the same Oracle version. In addition, replication allows
for concurrent read/write access of data.
Almost all replicated sites use asynchronous replication.
With asynchronous replication, messages are sent to the other servers and
no reply is needed. If a disaster occurred which destroyed the master,
some small amount of data could be lost. However, this window of
data loss is much smaller than that of a standby database, and non-destructive
failures will be reconciled once the failed server comes back on line.
A disadvantage of replication is that it does have a performance drain
on the system. Some CPU cycles will be spend on replication.
Throughput will be limited to a few hundred transactions per second with
Oracle8i, and less with earlier releases. Finally, replication will
not work with all "off the shelf" applications. The application must
be replication aware. Some of the other disaster recovery techniques
are less intrusive than replication, although they may be less flexible,
or have greater exposure to data loss.
Using Advanced Replication
To use Advanced Replication you need to have Oracle8 Enterprise Edition.
To set up a Replication Siter run $ORACLE_HOME\admin\catrep.sql and
catrepad from svrmgrl as internal.
Before you run "catrep.sql" create a new tablespace that will hold
the replication objects and change the "default tablespace" of "sys" to
the new tablespace. This will prevent the replication tables from growing
(as they will do from time to time) and causing your system tablespace
to fill.
Check with support, as there is at least one table that is already
created in the system tablespace by "catalog.sql" that you should also
recreate in another tablespace.
Using Synchronous Data Propagation
Synchronous, also known as real-time replication, applies any changes
or executes any replicated procedures at all sites participating in the
replication environment as part of a single transaction. If the DML or
procedure fails at any site, the entire transaction rolls back. Synchronous
replication ensures data consistency at all sites in real-time.
Synchronous replication uses the two-phase commit process. In a two-phase
commit environment, when an update to the master database is processed,
the master system connects to all other systems (slave databases) that
require the update, locks those databases at the record level and then
updates them simultaneously. If any connection to another system is not
available, the update will be rejected. So the DML operations take a little
longer than asynchronous.
Additionally, while query performance remains high because they are
performed locally, updates are slower because of the 2-phase commit protocol
that ensures that any updates are successfully propagated and applied to
the remote destination sites.
When an update is executed, a trigger associated with the table updates
is activated, causing the update to invoke the two-phase commit process
with all other databases that require the update.
Because the synchronous approach requires access to all slave databases
at the time of update, 100 percent network availability is required to
ensure that all transactions are completed successfully. The implication
of 100 percent availability is obvious -- without the network connections
a synchronous replication will not process, causing all update processing
to be suspended and potentially locking the application.
Restrictions
Because of the locking mechanism used by synchronous replication, deadlocks
can occur. When an application performs a synchronous update to a replicated
table, Oracle first locks the local row and then uses an AFTER ROW trigger
to lock the corresponding remote row. Oracle releases the locks when the
transaction commits at each site.
Using Asynchronous Data Propagation
Asynchronous replication, often referred to as store-and-forward replication,
is what most vendors recommend and is the type of replication currently
in vogue. captures any local changes, stores them in a queue, and, at regular
intervals, propagates and applies these changes at remote sites. With this
form of replication, there is a period of time before all sites achieve
data convergence.
If a system is unavailable, the server continues to track the unapplied
updates and will update the system when it is available. If the replication
process cannot be completed with all systems, all databases may not reflect
current information.
Asynchronous replication requires less networking and hardware resources
than does synchronous replication, resulting in better availability and
performance.
Asynchronous replication, however, means that the data sets at the
different master sites in the replication environment may be different
for a period of time before the changes have been propagated. Also, data
conflicts may occur in an asynchronous replication environment.
Asynchronous allows a store and forward method, so the refresh rate
is important, but if the network connection goes down then things can still
keep rolling.
Conflict Detection
If all sites of a master group communicate synchronously with one another,
applications should never experience replication conflicts. However, if
even one site is sending changes asynchronously to another site, applications
can experience conflicts at any site in the replicated environment.
If the change is being propagated synchronously, an error is raised
and a rollback will be required. If the change is propagated asynchronously,
Oracle automatically detects the conflicts and either logs the conflict
or, if you designate an appropriate resolution method, resolves the conflict.
You can change the propagation mode from asynchronous to synchronous
or viceversa for a master site. If you change the propagation mode for
a master site in a master group, you must regenerate replication support
for all master group objects. Also, a multimaster replication environment
may contain a mixture of both synchronous and asynchronous replication.
SETTING YOUR ENVIRONMENT FOR SYMMETRIC REPLICATION
Required Tablespaces:
Before you create
and administer a replication environment, you need to know the following:
o System tablespace : replication needs an additional
15 mb of system space.
o Rollback segment : (at least 2) should be larger than
normal.
o User tablespace.
o Temporary tablespace.
Database Scripts:
All the following scripts are located in $ORACLE_HOME/rdbms/admin
and need to be run if they have not been run yet.
o
catalog.sql
o catproc.sql <<< will run catsnap.sql and dbmssnap.sql
o catrep.sql <<< for symmetric replication ;
this script takes a long time to run. (+- 1 Hour)
o pupbld.sql <<< not required for replication
but needed to avoid "user profile ... error messages.
Initialization Parameters in init<SID>.ora :
o job_queue_processes : at least 2
o job_queue_interval
: should be less than the time interval to push data along the dblink.
o shared_pool_size
: at least 15 mb ; 25mb suggested.
o distributed_lock_timeout : default 300 sec ( 5
min )
o distributed_transactions : maximum 10
o global_names
: for Replication to work it should be set to TRUE.
o open_links : minimum 5
Global Names for the databases:
o Choose global names as appropriate for the environment.
o To assign a global name for the database :
o sqlplus sys/<password>
o alter database rename global_name to <a name>;
Sql*Net Version 2 files :
The following files are needed.
o tnsnames.ora
o listener.ora
NOTE: Replication needs Sql*Net version 2 ; Sql*Net version 1
is not supported because it does not support global naming.
Private Database Links :
o Create the necessary private database links using connecters
but not aliases.
/*************************************************************************
HOW TO ADD ADDITIONAL MASTER SITES
*************************************************************************/
--After you have defined your master group at the MASTERDEF
site (the
--site where the master group was created becomes the
MASTER DEFINITION
--site by default), you can define the other sites that
will participate
--in the replicated environment. You might have guessed
that you will be
--adding the ORC2.WORLD and ORC3.WORLD sites to our replicated
environment.
BEGIN
DBMS_REPCAT.ADD_MASTER_DATABASE (
gname => 'SCOTT_MG',
master => 'ORC2.WORLD',
use_existing_objects => TRUE,
copy_rows => TRUE,
propagation_mode => 'ASYNCHRONOUS');
-- SYNCHRONOUS mode propagation is used only in a multi-master
environment.
END;
/