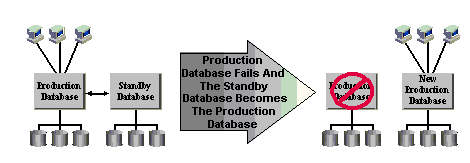
Figure 1: Standby Database Becomes the Production Database After a Disaster
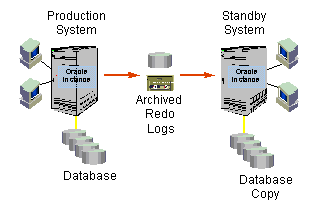
After the standby database is created, updates and changes made to the production database must be propagated to the standby database so that the two databases remain synchronized. The primary mechanism used to ensure database recovery is the logging of changes to the database. The log files contain all the data needed to perform database recovery. The log files record every change made to data and metadata in the database and are the vehicle by which changes made at the production database are propagated to a standby database. As archived redo logs are generated on the production database, they are applied to the standby database. This enables the standby database to remain synchronized with the production database.
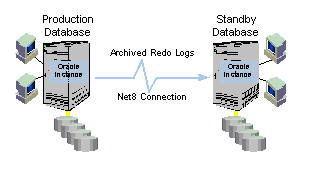
The archive log destinations are assigned user-defined attributes to implement a disaster planning policy. For example, archive log destinations can have the attributes of optional or mandatory. Optional specifies that archival to the destination is not required. Mandatory specifies the archival must succeed before the online log file can be reused. It is also possible to specify the minimum number of archive log destinations that must succeed before allowing the reuse of online log files. These attributes ensure a user-defined minimum number of copies of the archive logs that are created to assure recoverability, yet prevent networking errors or out of space conditions from stalling the production database. Another attribute can also be used to automatically retry sending the archive log to the destination. If a networking error or out of space condition prevents a successful log file creation, the Oracle database after a user specified interval, automatically re-attempts the archive operation. These capabilities ensure the standby database remains synchronized with the production database and is ready to take over in the event of a disaster.

Finally, a full standby database is not required to remotely receive and store the archive logs. A compatible standby database control file at the destination site is all that is required to accept and record the fact that archived log files have been received from the production database. This can be used to automate the transmission and storage of log files at a remote site without incurring the cost of replicating the entire production database. While this ensures backups of archived log files will exist offsite, failover to the standby site would be delayed until after the database is restored and the archive logs applied.
Oracle8i offers administrators the ability to create multiple ARCHiver processes. Multiple ARCHiver processes improve performance by preventing the production database from stalling when it ships logs through a network to a remote standby database. Multiple ARCHiver processes also prevent bottlenecks that can occur when log file switches occur faster than a single ARCHiver process can write the archive logs. This can occur on a database with heavy update transaction rates where redo logs entries are generated faster than a single ARCHiver process can archive them.
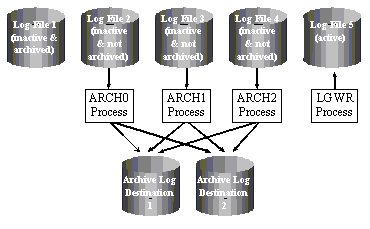
Running multiple ARCH processes eliminates archiving as a bottleneck and can be used on a production database independent of, or in conjunction with, a standby database.
In Oracle8i, administrators can take the standby database out of recovery mode and open it in read-only mode. This can be used to temporarily offload query or report processing from the production database to the standby database. Queries against read-only databases are transactionally consistent and do not display uncommitted data. This is possible because of Oracle's read consistency architecture.
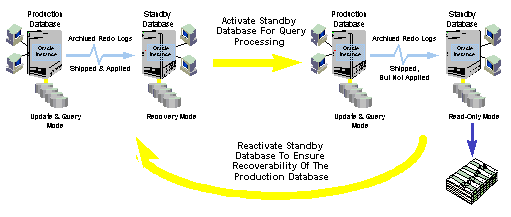
Read-only mode allows sort segments and other data to be written to temporary tablespaces, yet prevents other modifications to the data files or redo logs that would invalidate the standby database. While in read-only mode, a standby database can continue to automatically receive the archive redo logs from the production database, so they are available if required. When the query processing is complete, the standby database can be returned to sustained or manual recovery mode, without re-cloning the production database, and the queued logs are applied. This provides more productive resource usage while maintaining high database availability.
Many mission-critical installations maintain an on-disk backup of the production database. This makes it easy to quickly restore the database in the event of a media failure or user error, without incurring a lengthy restore from tape. The read-only database functionality also allows these on-disk backups to be used for query and report processing.